javase-可变集合
|总字数:4.9k|阅读时长:20分钟|浏览量:|
集合的体系结构
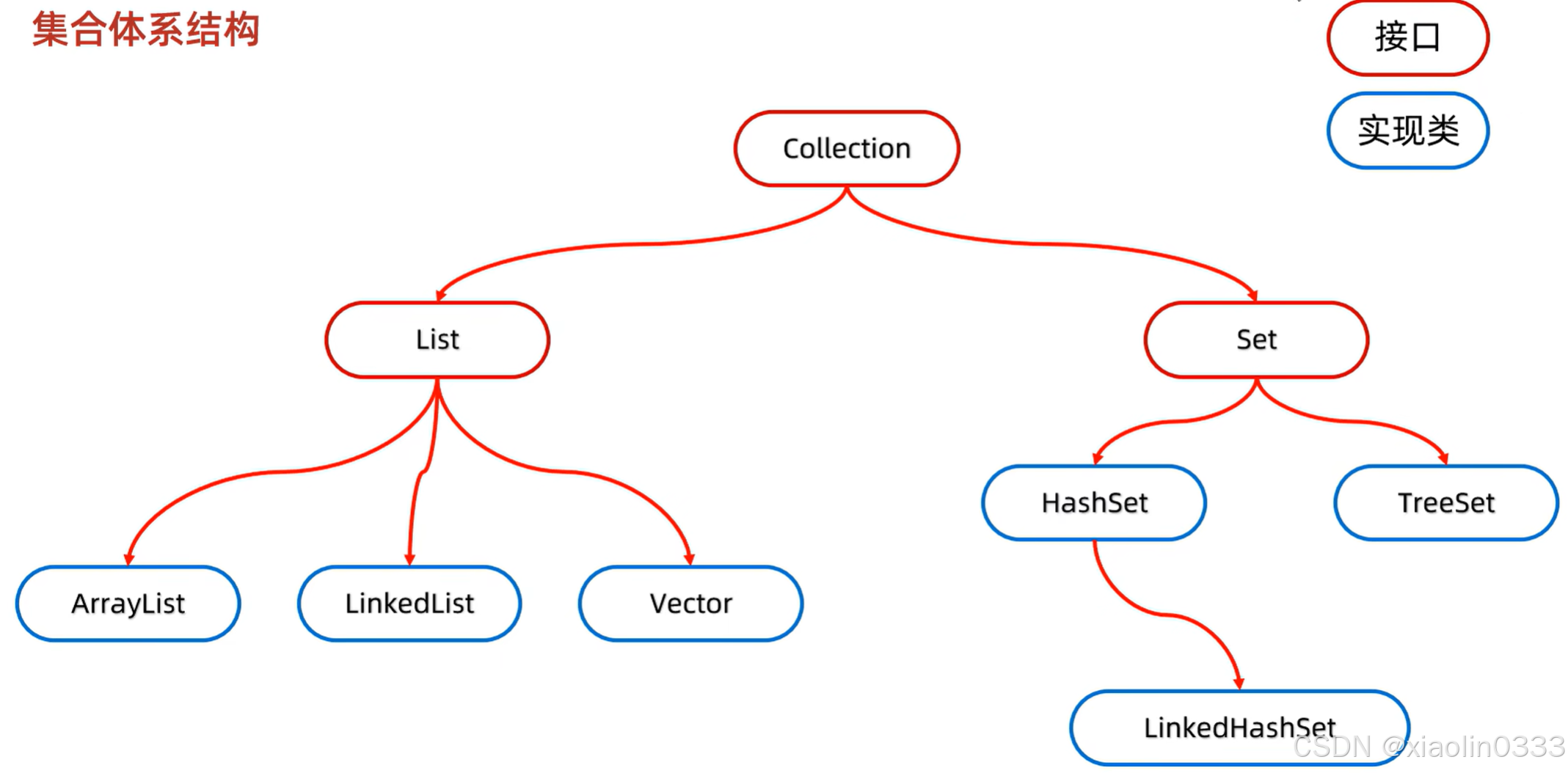
List:添加的元素是有序、可重复、有索引的。
Set:添加的元素是无序、不重复、无索引的。
Collection
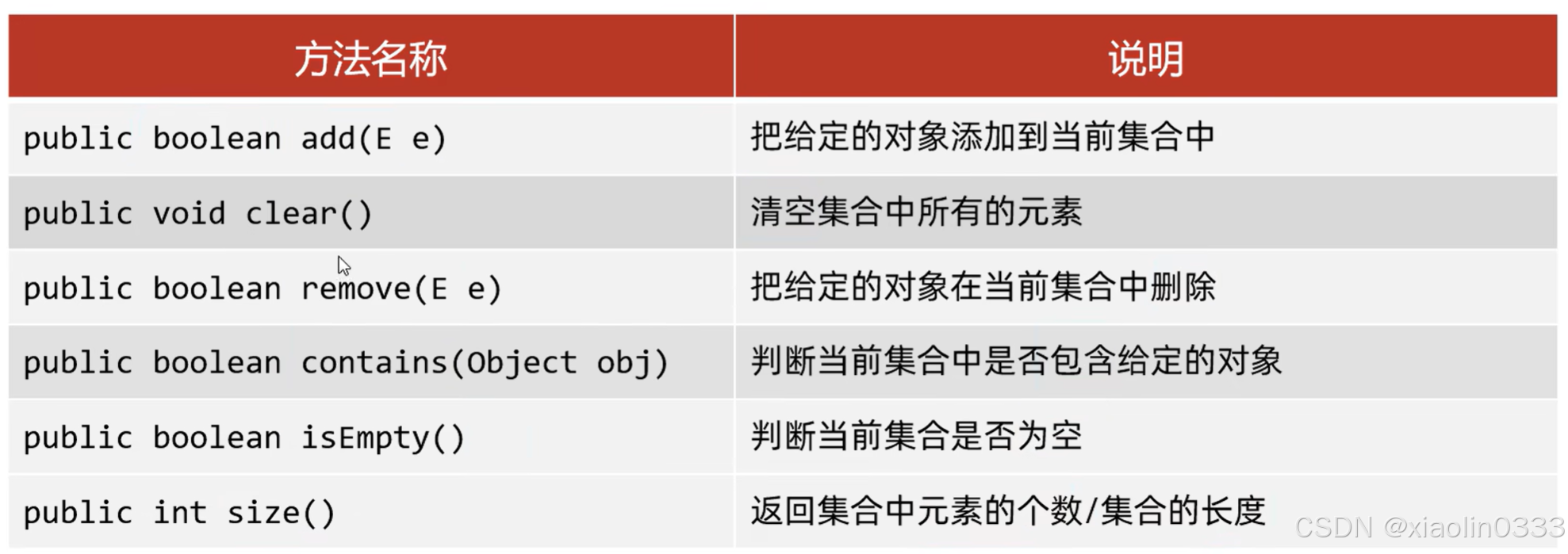
是单列集合的祖宗接口,它的功能是所有单列集合都可以继承使用。
基本方法
public class Demo01 {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.remove("aaa");
coll.clear();
boolean isExists = coll.contains("aaa");
boolean isEmpty = coll.isEmpty();
int size = coll.size();
}
}
|
遍历方式
迭代器遍历
迭代器Iterator是集合专用的遍历方式
public class Demo02 {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
Iterator<String> it = coll.iterator();
while(it.hasNext()) {
String str = it.next();
System.out.println("str = " + str);
}
}
}
|
- 迭代器遍历不依赖索引
- 如果迭代器遍历到最后一个位置了,还强行使用it.next(),会报错:NoSuchElementException
- 迭代器遍历完毕,指针不会复位
- 循环中只能用一次next方法【如果想要使用第二次,最好在循环里多判断一次hasNext()】
- 迭代器遍历时,不能使用集合的方法进行添加或删除,会报错:ConcurrentModificationException
- 但是可以用迭代器提供的remove()方法进行删除
- 添加暂时无解
增强for遍历
增强for是为了简化迭代器的书写,内部原理就是迭代器,单列集合、数组才能用增强for遍历。
修改增强for中的变量(第三方变量),不会改变集合原本的数据
lambda表达式遍历
public class Demo04 {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.forEach(s -> System.out.println(s));
}
}
|
forEach的底层就是增强for
总结
迭代器:删除元素
读:增强for 或 lambda
List
有序、有索引、可重复
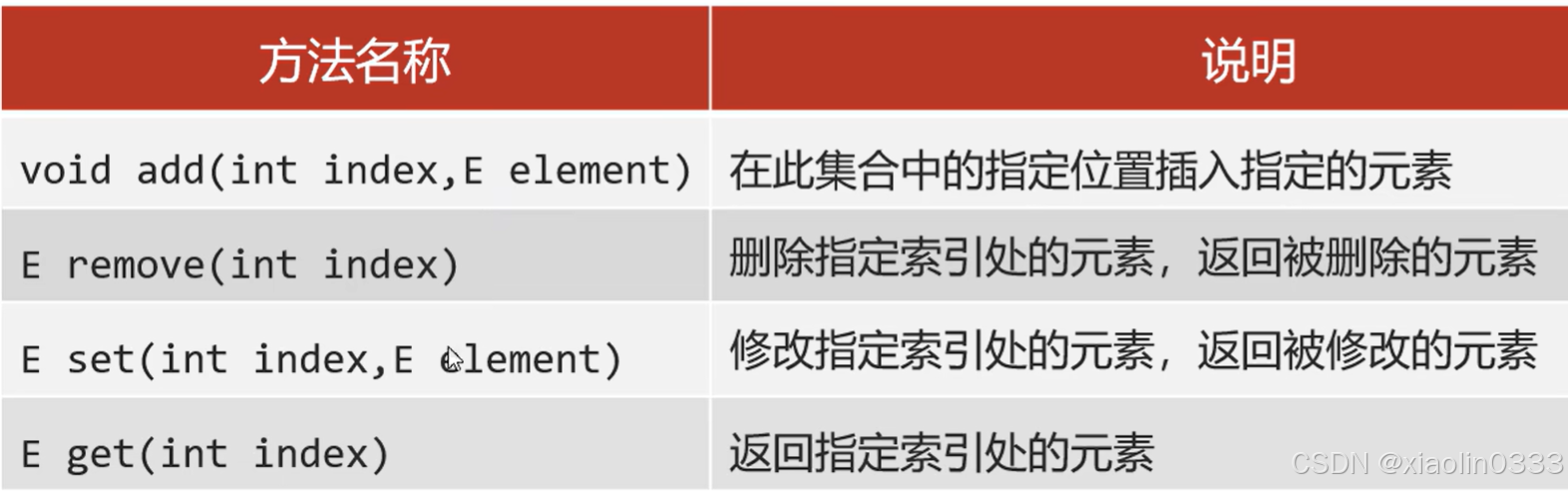
List集合的方法 = Collection的方法 + 索引操作的方法
List中特有的方法
Collection的方法List都继承了
- 如果在调用remove()方法时,remove(int idx) 和 remove(Object obj)都可以匹配上,那么优先调用实际参数和形参保持一致的方法。
索引操作的方法
public class Demo05 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(1, 4);
Integer remove = list.remove(1);
Integer i = Integer.valueOf(1);
boolean isRemove = list.remove(i);
Integer res = list.set(0, 33);
res = list.get(0);
}
}
|
List中独有的遍历方式
Collection的遍历方式List都可以用
List集合的遍历方式 = Collection中的遍历方式 + 列表迭代器遍历 + 普通for遍历
Collection中的遍历方式 + 普通for遍历
public class Demo02 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
Iterator<String> it = list.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
for(String s : list) {
System.out.println(s);
}
list.forEach(s -> System.out.println(s));
for(int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
|
列表迭代器
public class Demo03 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
ListIterator<String> it = list.listIterator();
while (it.hasNext()) {
String str = it.next();
if("bbb".equals(str)) {
it.add("zzz");
}
}
}
}
|
列表迭代器 相比 迭代器多出了添加元素的方法
五种方式的对比
迭代器:需要删除元素
列表迭代器:需要添加元素
增强for、lambda:仅遍历元素
普通for:想操作索引
ArrayList
ArrayList的底层是数组的,ArrayList中的方法 = List中的方法
底层原理
- 利用空参创建的集合,在底层创建一个默认长度为0的数组。
- 添加第一个元素,底层会创建一个长度为10的数组。
- 存满时,会扩容1.5倍。
- 如果一次添加多个元素,1.5倍放不下,则新数组的长度以实际长度为准。
LinkedList
LinkedList的底层是双链表,查询慢、增删快。
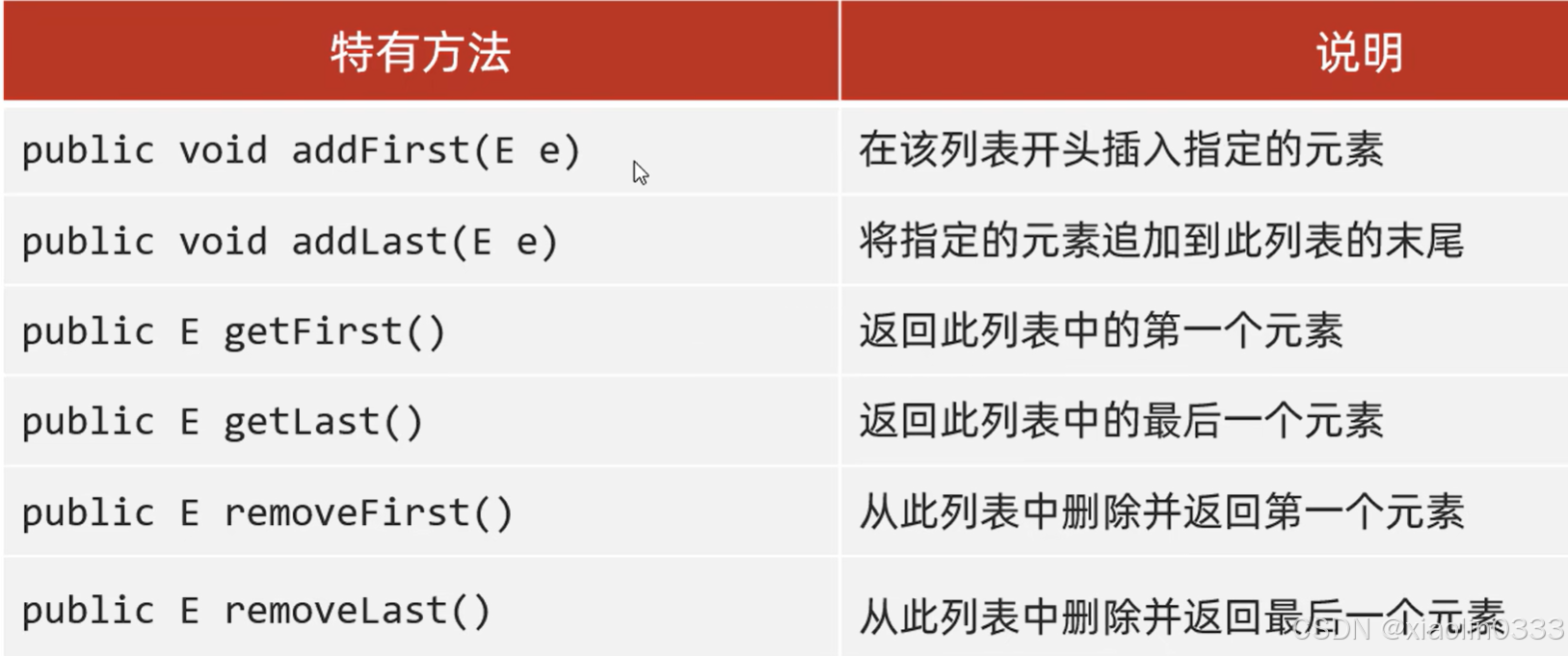
LinkedList中的方法 = List中的方法 + LinkedList中独有的方法(少用)
LinkedList中独有的方法
泛型
- 泛型:在编译阶段约束操作的数据类型
- 泛型只支持引用数据类型(基本数据类型要转成包装类才行)
- 不写泛型,默认是Object类型
- 如果没有给集合指定泛型,默认所有的数据类型都是Object类型,此时可以往集合中添加任意类型的数据,在获取数据的时候,无法使用元素的特有行为。
Java中的泛型是伪泛型
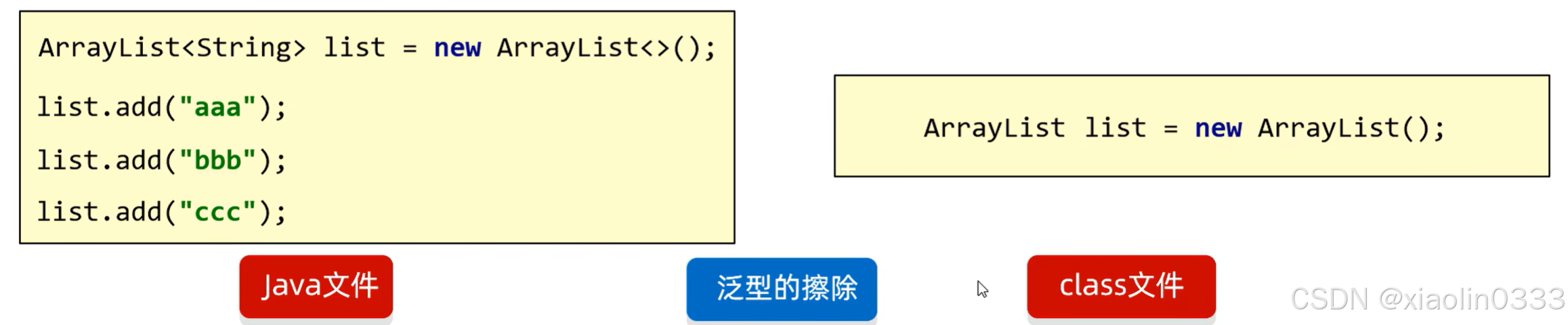
泛型可以定义的地方
泛型类(类后边)
使用场景:当定义一个类时,某个变量的数据类型不确定,就可以定义带有泛型的类
修饰符 class 类名<类型> {}
public class User<E> {
E sex;
}
|
class MyArrayList<E> {
Object[] obj = new Object[10];
int size = 0;
public boolean add(E e) {
obj[size] = e;
++size;
return true;
}
public E get(int idx) {
return (E)obj[idx];
}
@Override
public String toString() {
return Arrays.toString(obj);
}
}
public class Demo02 {
public static void main(String[] args) {
MyArrayList<String> list = new MyArrayList<>();
list.add("A");
list.add("B");
list.add("C");
System.out.println(list);
}
}
|
泛型方法(方法上边)
方法中形参类型不确定
修饰符 <类型> 返回值类型 方法名(类型 变量名) {}
public <T> void show(T t) {}
|
class ListUtil {
public static <T> void addAll(ArrayList<T> list, T...elements) {
for(T e : elements) {
list.add(e);
}
}
}
public class Demo03 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
ListUtil.addAll(list, "aaa", "bbb", "ccc");
}
}
|
泛型接口(接口后边)
- 方式1:实现类给出具体类型
- 方式2:实现类延续泛型,创建对象时再确定
修饰符 interface 接口名<类型> {}
public interface List<E> {}
|
interface MyList<K> {
void add(K element);
}
class MyArrayList1 implements MyList<String> {
@Override
public void add(String element) {
}
}
class MyArrayList2<K> implements MyList<K> {
@Override
public void add(K element) {
}
}
public class Demo04 {
public static void main(String[] args) {
MyArrayList1 list1 = new MyArrayList1();
MyArrayList2<String> list2 = new MyArrayList2();
}
}
|
泛型的继承和通配符
class Ye{}
class Fu extends Ye{}
class Zi extends Fu{}
public class Demo05 {
public static void method(ArrayList<Ye> list) {}
public static void main(String[] args) {
ArrayList<Ye> list1 = new ArrayList<>();
ArrayList<Fu> list2 = new ArrayList<>();
ArrayList<Zi> list3 = new ArrayList<>();
method(list1);
list1.add(new Ye());
list1.add(new Fu());
list1.add(new Zi());
}
}
|
如果方法形参是一个集合,集合中的数据类型不确定,可以用泛型方法
public class Demo06 {
public static <T> void method(ArrayList<T> list) {}
public static void main(String[] args) {
ArrayList<Ye> list1 = new ArrayList<>();
ArrayList<Fu> list2 = new ArrayList<>();
ArrayList<Zi> list3 = new ArrayList<>();
method(list1);
method(list2);
method(list3);
}
}
|
泛型通配符
上边代码存在一个问题:这种情况下它可以接受任意的数据类型
如果希望以后这个参数的数据类型只能是:Ye、Fu、Zi类,可以用泛型的通配符
- ? extends E:表示可以传递E或E所有的子类类型
- ? super E:表示可以传递E或E所有的父类类型
public class Demo06 {
public static<E> void method(ArrayList<E> list) {}
public static void method1(ArrayList<? extends Ye> list) {}
public static void method2(ArrayList<? super Zi> list) {}
public static void main(String[] args) {
ArrayList<Ye> list1 = new ArrayList<>();
ArrayList<Fu> list2 = new ArrayList<>();
ArrayList<Zi> list3 = new ArrayList<>();
method1(list1);
method1(list2);
method1(list3);
method2(list1);
method2(list2);
method2(list3);
}
}
|
应用场景
如果定义类、方法、接口时,类型不确定,可以定义泛型类、泛型方法、泛型接口。
如果类型不确定,但是能知道以后只能传递某个继承体系中的,可以使用泛型通配符。
单列集合Set
无序、不重复、无索引
Set集合的方法 = Collection的方法
【注】:所有Set集合的底层原理都是new Map()
public class Demo01 {
public static void main(String[] args) {
Set<String> st = new HashSet<>();
boolean r1 = st.add("A");
boolean r2 = st.add("A");
Iterator<String> it = st.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
for (String s : st) {
System.out.println(s);
}
st.forEach(x -> System.out.println(x));
}
}
|
Set集合的实现类:
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TreeSet:可排序、不重复、无索引
HashSet
HashSet底层采用哈希表存储数据
- 哈希表的组成:
- JDK8之前:数组 + 链表
- JDK8开始:数组 + 链表 + 红黑树
哈希值
对象的整数表现形式,根据hashCode()算出来的int类型的整数
hashCode()定义在Object类中,所有的对象都可以调用,默认使用地址值进行计算
一般情况需要重写hashCode()方法,利用对象内部的属性值计算哈希值
- 如果没有重写hashCode()方法,不同对象计算出的hashCode是不不同的
- 如果重写hashCode()方法,不同对象只要属性值相同,计算出的哈希值是一样的
- 小概率:不同属性值或不同地址值计算出来的哈希值也可能一样(哈希碰撞)
底层原理
- 创建一个默认长度为16,默认加载因子为0.75的数组
hashSet的扩容时机:
- 16 * 0.75 = 12,当数组中元素达到12个元素,就会扩容成原先的2倍
- (JDK8开始)链表的长度 > 8 且 数组长度 ≥ 64,当前链表会自动转成红黑树
- 根据数组的哈希值与数组的长度计算元素应存入的位置
int idx = (数组长度 - 1) & 哈希值;
- 判断当前位置是否为null
- 如果是null,直接存入
- 如果不是null,调用equals()方法比较属性值
- 一样:不存
- 不一样:存入数组,形成链表
- JDK8以前:新数组存入数组,老元素挂在新数组下边
- JDK8开始:新元素直接挂在老元素下边
如果集合中存储的是自定义对象,必须重写hashCode和equals方法
LinkedHashSet
- 有序、不重复、无索引
- 有序:存储和取出元素的顺序一致
- 原理:底层仍然是哈希表,只是每个元素有额外多了一个双链表的机制记录存储的顺序
TreeSet
public class Demo05 {
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(1);
set.add(4);
set.add(2);
set.add(5);
set.add(3);
System.out.println(set);
}
}
|
TreeSet集合默认排序规则
- 数值类型(Integer、Double):默认按照从小到大顺序排序
- 字符、字符串类型:默认按照字符在ASCII码表中的顺序升序排序
TreeSet集合的两种比较方式
【注】:
如果使用TreeSet集合存储自定义类型,不需要重写HashCode和equals方法,但是需要在类里边指定排序规则。
方式1:默认排序 / 自然排序
Javabean实现Comparable接口指定比较规则。
@Data
@AllArgsConstructor
@NoArgsConstructor
class Stu implements Comparable<Stu> {
private String name;
private int age;
@Override
public int compareTo(Stu o) {
return this.getAge() - o.getAge();
}
}
public class Demo06 {
public static void main(String[] args) {
TreeSet<Student> set = new TreeSet<>();
set.add(new Student("xiaoshi", 18));
set.add(new Student("xiaohan", 19));
set.add(new Student("xiaolin", 20));
set.add(new Student("03", 22));
System.out.println(set);
}
}
|
方式2:比较器排序
创建TreeSet对象时,传递比较器Compartor指定规则
public class Demo07 {
public static void main(String[] args) {
TreeSet<String> set = new TreeSet<>((o1, o2) -> o1.length() == o2.length() ? o1.compareTo(o2) : o1.length() - o2.length());
set.add("c");
set.add("ab");
set.add("df");
set.add("quer");
System.out.println(set);
}
}
|
两种比较规则的使用场景
默认使用第一种,如果第一种不能满足规则,就使用第二种。
List、Set的使用场景
- 如果想要集合中的元素可重复:ArrayList、基于数组
- 如果想要集合中的元素可重复,且增删操作多余查询:LinkedList、基于链表
- 如果想对集合中的元素去重:HashSet、基于哈希表
- 如果想对集合中的元素去重,且保证存储顺序:LinkedHashSet、基于哈希表和双链表,效率低于HashSet
- 如果想对集合中的元素进行排序:TreeSet、基于红黑树
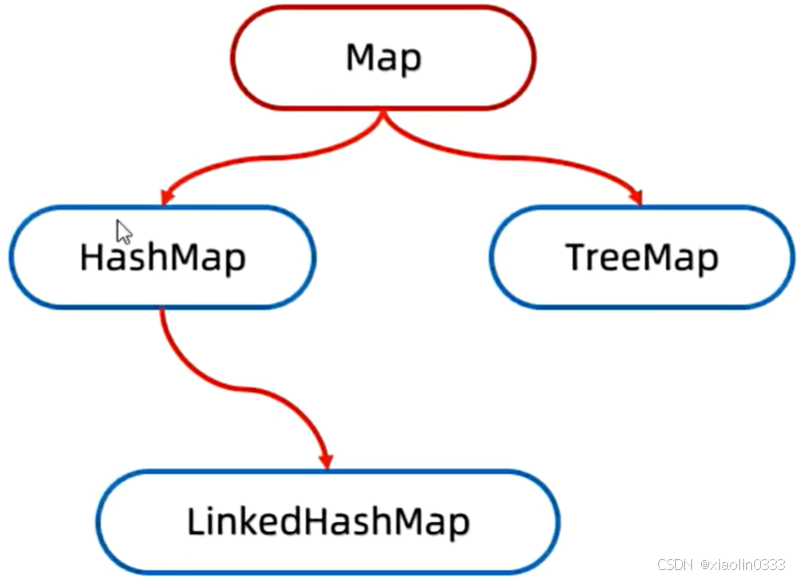
双列集合Map
- 一次需要存一对数据(键-值)
- 键不能重复,值可以重复
- 键值是一一对应的,每个键只能找到对应的值
- 键 + 值 称为“键值对”,在java中叫做“Entry对象”
体系结构
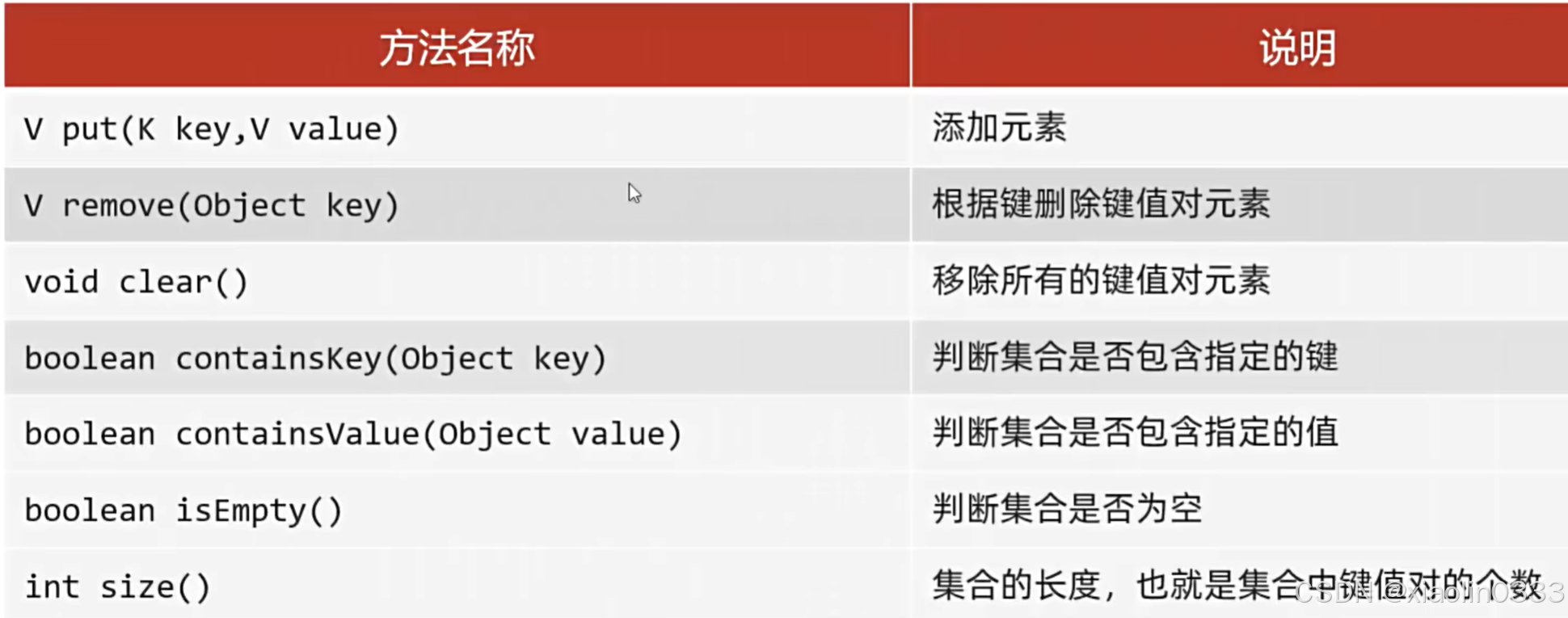
常见的API
Map是双列集合的顶层接口,他的功能是全部双列集合都可以继承使用的。
public class Demo01 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("杨过", "小龙女");
String res = map.put("工藤新一", "毛利兰1");
res = map.put("工藤新一", "毛利兰");
map.put("服部平次", "远山荷叶");
boolean keyResult = map.containsKey("工藤新一");
boolean valueResult = map.containsValue("毛利兰");
boolean isEmpty = map.isEmpty();
int size = map.size();
String removeValue = map.remove("杨过");
map.clear();
}
}
|
遍历方式
键找值
public class Demo02 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("怪盗基德", "中森青子");
map.put("工藤新一", "毛利兰");
map.put("服部平次", "远山荷叶");
Set<String> keys = map.keySet();
keys.forEach(k -> System.out.println(k + "-" + map.get(k)));
}
}
|
键值对
public class Demo03 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("怪盗基德", "中森青子");
map.put("工藤新一", "毛利兰");
map.put("服部平次", "远山荷叶");
Set<Map.Entry<String, String>> entries = map.entrySet();
for(Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey() + "-" + entry.getValue());
}
}
}
|
Lambda表达式
public class Demo04 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("怪盗基德", "中森青子");
map.put("工藤新一", "毛利兰");
map.put("服部平次", "远山荷叶");
map.forEach((k, v) -> System.out.println(k + "-" + v));
}
}
|
HashMap
HashMap中的方法 = Map中的方法
底层原理
同HashSet,就是在计算hash值的时候调用的是键的hashCode()方法
- 底层也是哈希表结构
- 依赖hashCode()和equals()方法保证键的唯一
- 如果键存储的是自定义对象,需要重写hashCode()和equals()方法
LinkedHashMap
有序、不重复、无索引
原理:底层数据结构仍是哈希表,只是每一个键值对元素又额外多了一个双链表机制记录存储的顺序。
TreeMap
- 底层同TreeSet,都是红黑树结构。
- 由键决定特性:不重复、无索引、可排序(对键排序)
- 默认按照键从小到大排序,也可以自己规定键的排序规则。
排序规则
方法1:默认排序/自定义排序
@Data
@AllArgsConstructor
@NoArgsConstructor
class Stu implements Comparable<Stu> {
String name;
int age;
@Override
public int compareTo(Stu o) {
if(this.age != o.age) {
return this.age - o.age;
}
return this.name.compareTo(o.name);
}
}
public class Demo08 {
public static void main(String[] args) {
TreeMap<Stu, String> map = new TreeMap<>();
map.put(new Stu("zhangsan", 23), "江苏");
map.put(new Stu("lisi", 24), "江苏");
map.put(new Stu("wangwu", 25), "江苏");
System.out.println(map);
}
}
|
方法2:比较器排序
public class Demo07 {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>((k1, k2) -> k2 - k1);
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
System.out.println(map);
}
}
|
Map的使用场景
HashMap:默认(效率最高)
LinkedHashMap:保证存取有序
TreeMap:保证排序
Collections:集合的工具类










