安装ElasticSearch
- Lucene:Java语言的搜索引擎类库,易扩展;高性能(基于倒排索引)
- Elasticsearch基于Lucene,支持分布式,可水平扩展;提供Restful接口,可被任何语言调用
- Elasticsearch结合kibana、logstash、Beats,是一套完整的技术栈,被叫做ELK。

安装ElasticSearch
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
--restart=always \
elasticsearch:7.12.1
|
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" :配置JVM的最大最小内存-e "discovery.type=single-node":配置运行模式(集群模式、单点模式)-v es-data:/usr/share/elasticsearch/data:es的数据存储目录-v es-plugins:/usr/share/elasticsearch/plugins:es的插件目录-p 9200:9200:访问的http端口-p 9300:9300:集群间通信端口
查看es的日志: docker logs -f es

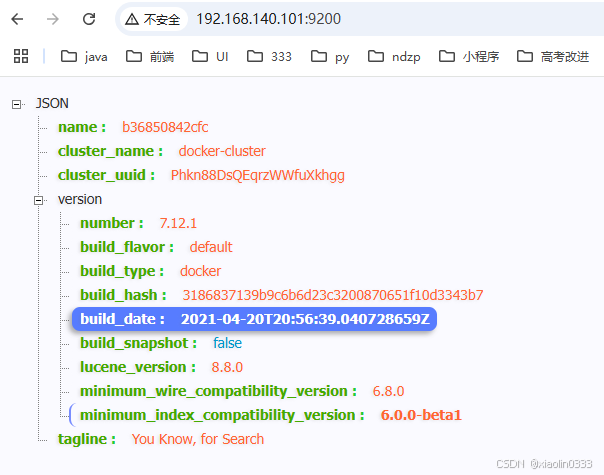
安装Kibana
Kibana是个图形界面,帮助我们连接es
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
--restart=always \
kibana:7.12.1
|
-e ELASTICSEARCH_HOSTS=http://es:9200 \:因为kibana和es在同一个网络下,所以可以通过容器名直接连接es

安装成功后,在浏览器输入:http://192.168.140.101:5601/,看到响应即安装成功。
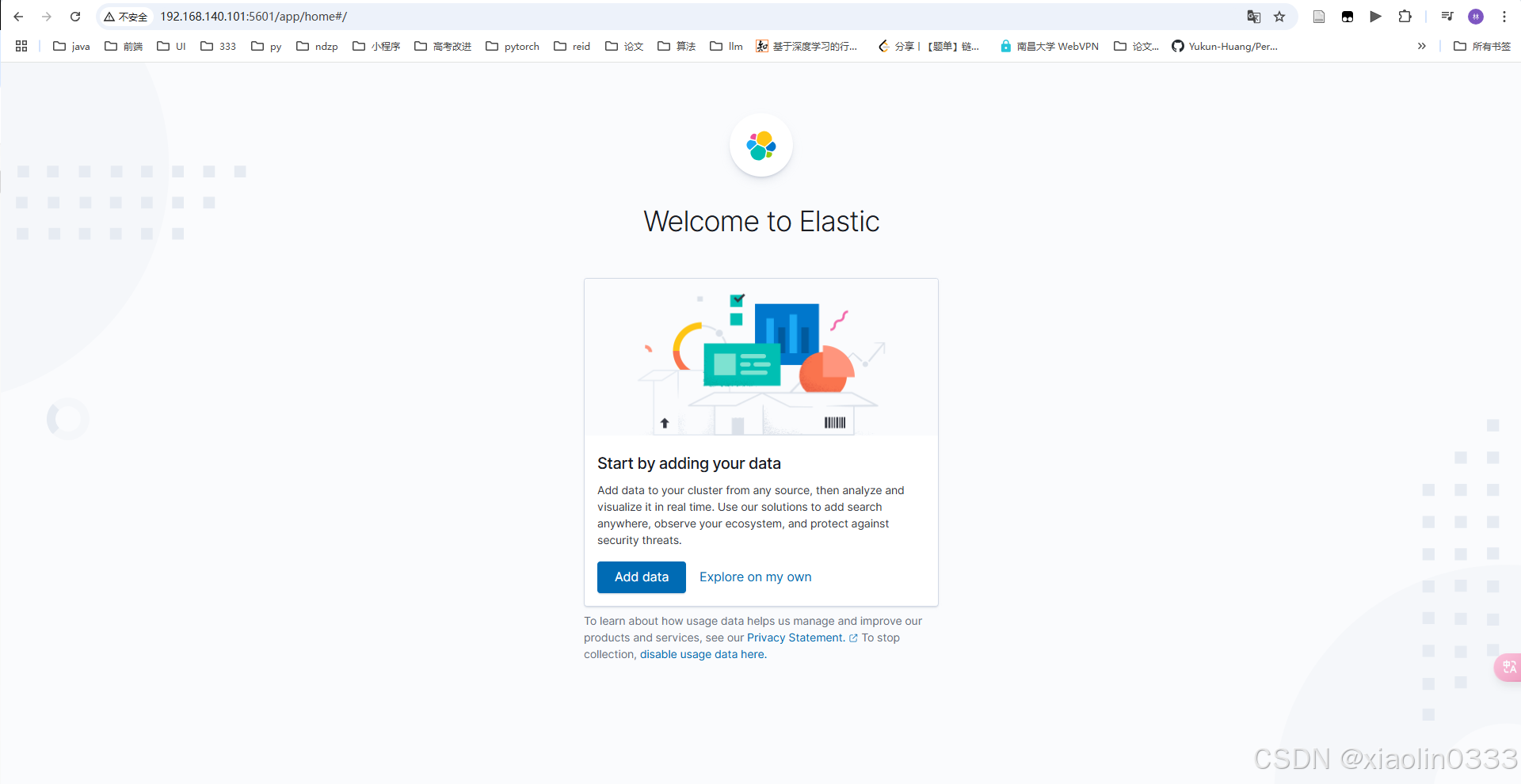
可以利用kibana中Dev Tools控制台向es发送http请求
倒排索引
MySQL采用的是正向索引:
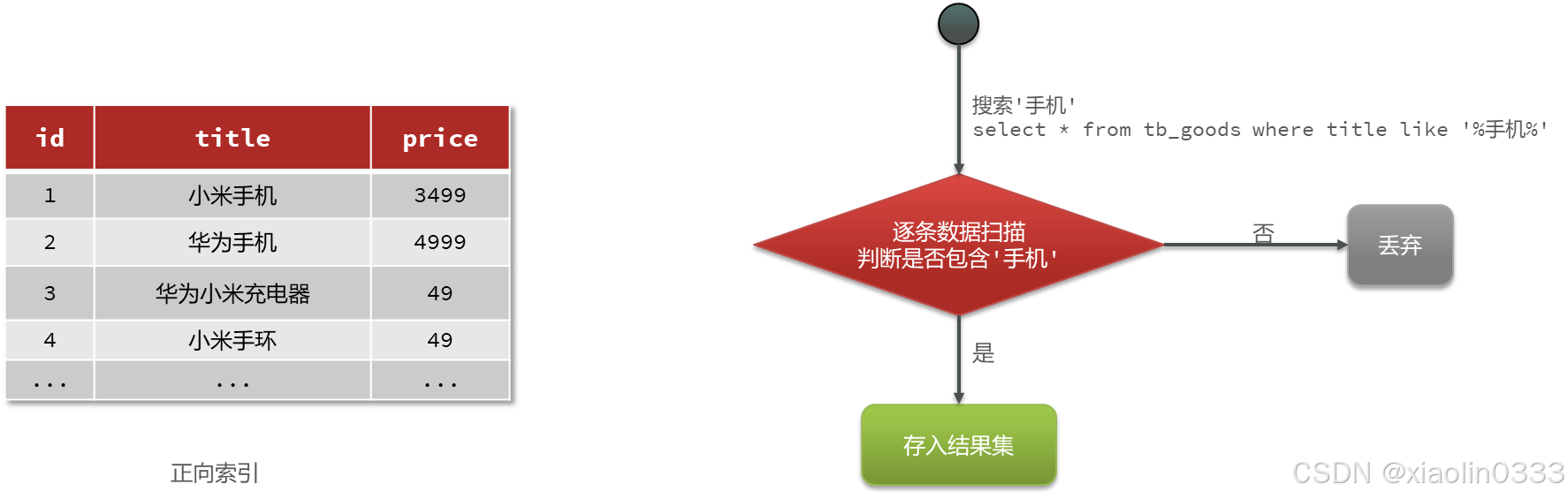
查询词条时需要逐行遍历文档,再判断文档中是否包含了词条
Elasticsearch采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语
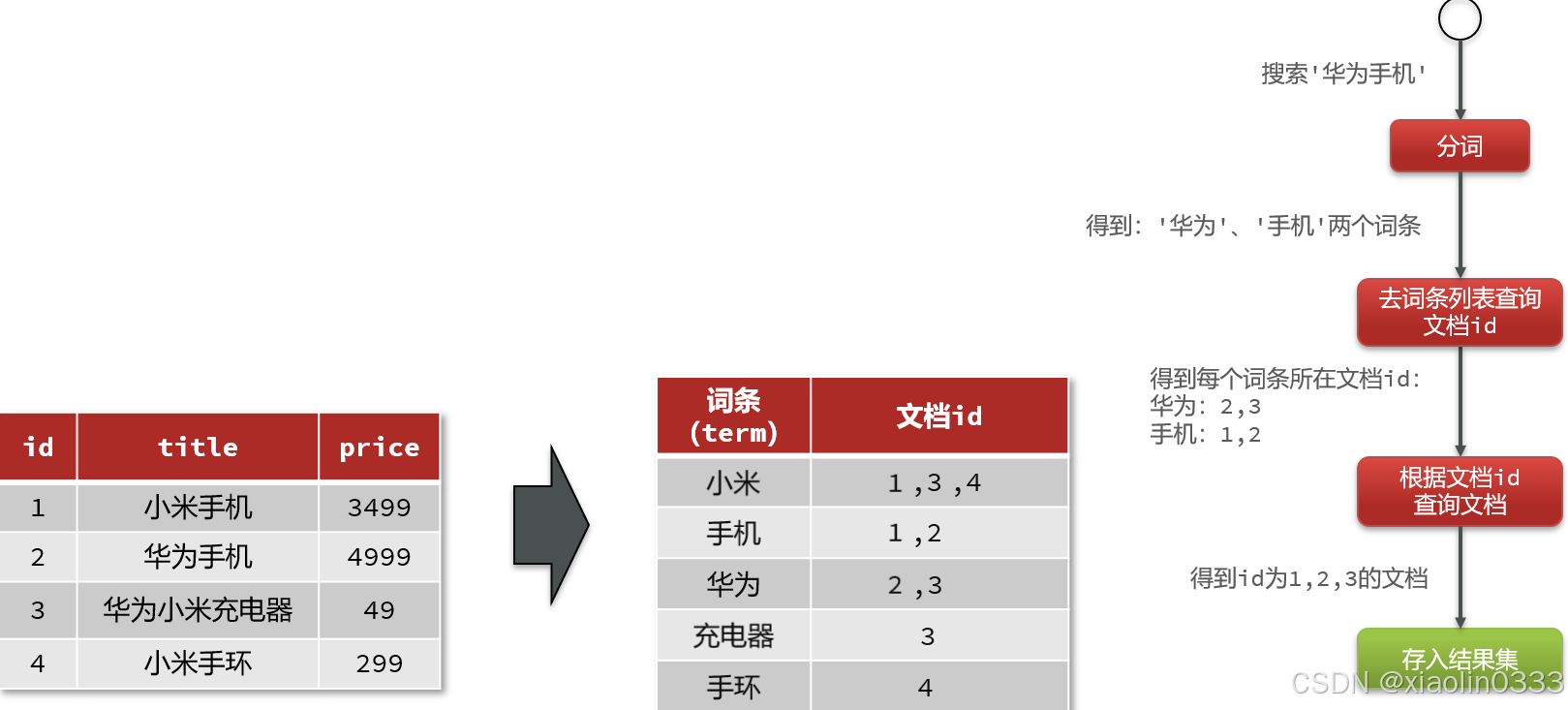
用户搜索的时候,先对用户搜索的数据进行分词,将分词后的词条放到词条列表中得到文档id,根据文档id去文档列表中查询。虽然有两次查询,但是每次查询都是有索引,搜索速度快。
IK分词器
中文分词往往需要根据语义,比较复杂,这就需要用到中文分词器,例如:IK分词器。
下载地址:IK分词器
安装IK分词器
只需要把IK分词器下载后放到es的插件目录后重启es即可生效。
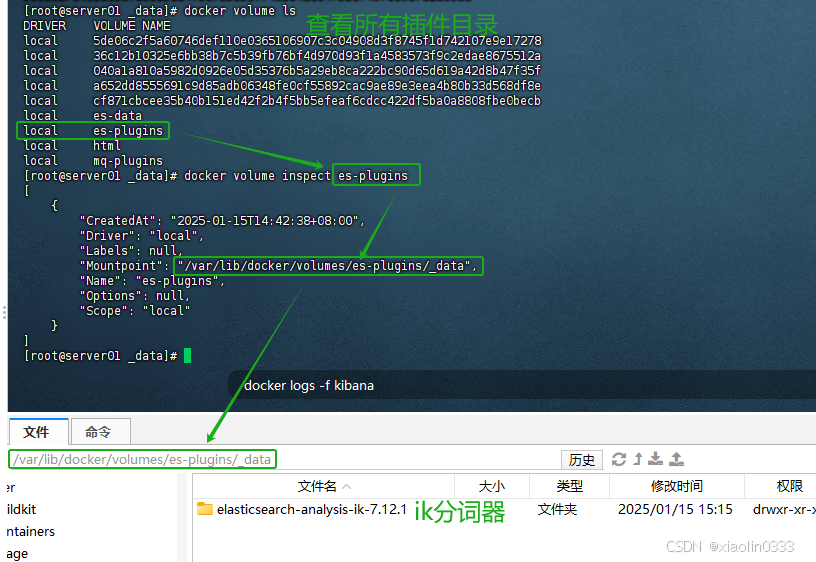
测试IK分词器是否安装成功
ik_smart
智能切分,粗粒度
POST /_analyze
{
"analyzer": "ik_smart",
"text": "今天天气真好"
}
|
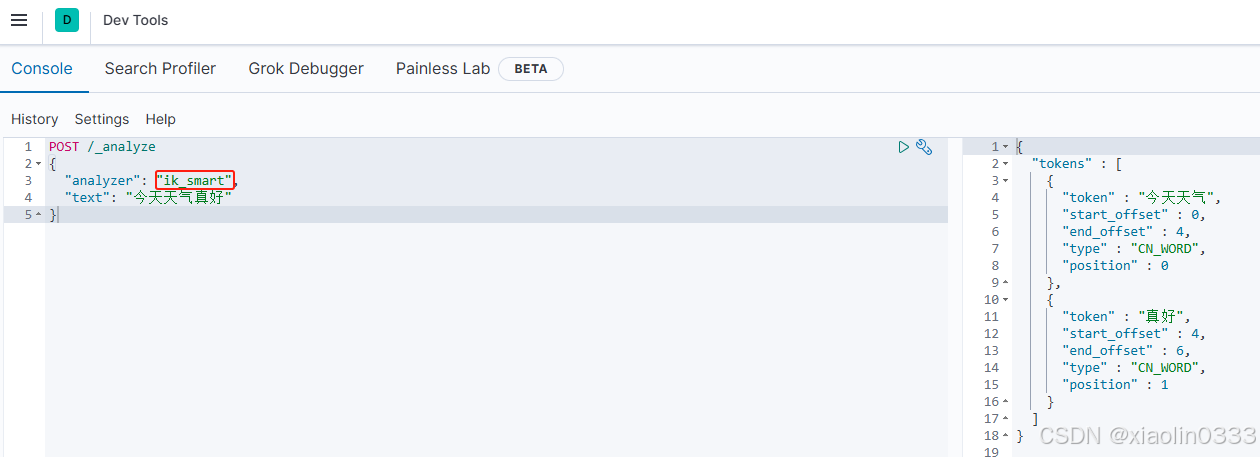
ik_max_word
最细切分,细粒度IK分词器
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "今天天气真好"
}
|
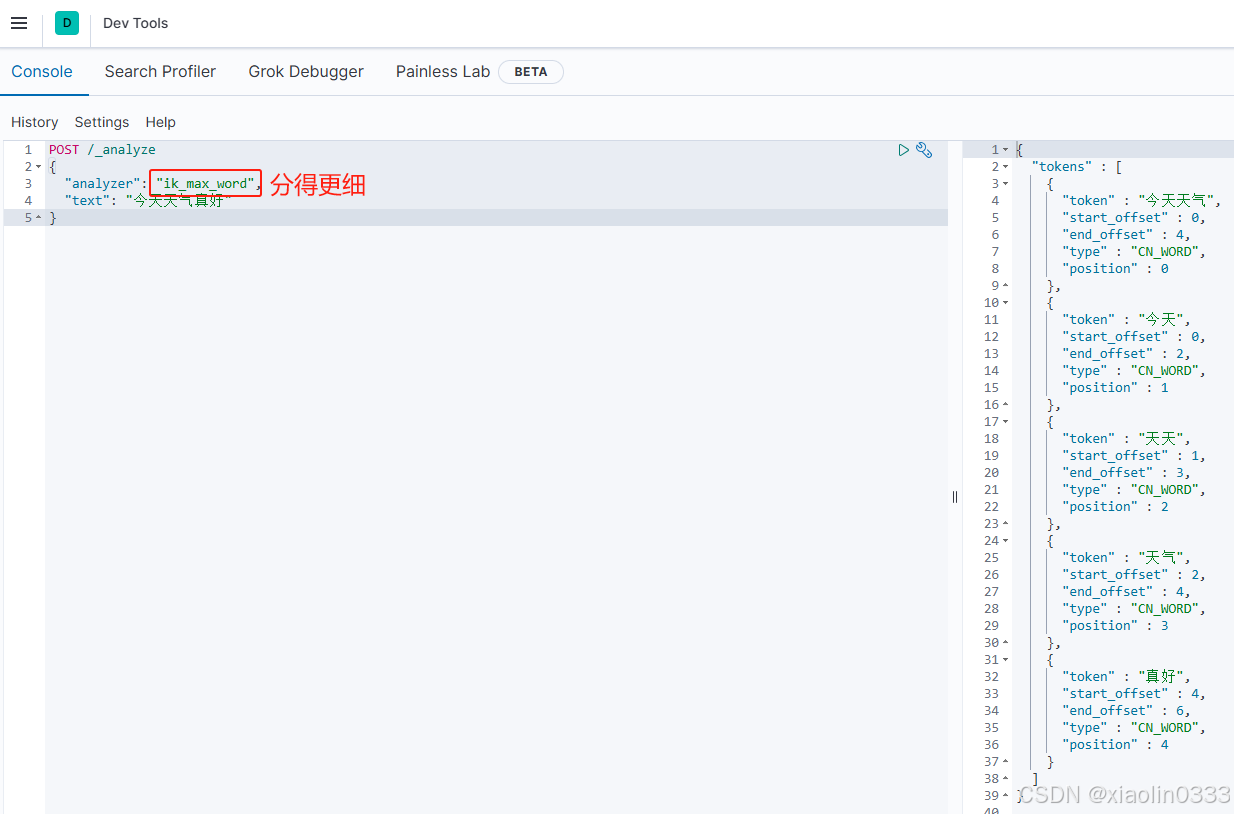
自定义词典
可以在ik插件的config目录下的IKAnalyzer.cfg.xml文件配置扩展词典、停止词典
ElasticSearch中基础概念
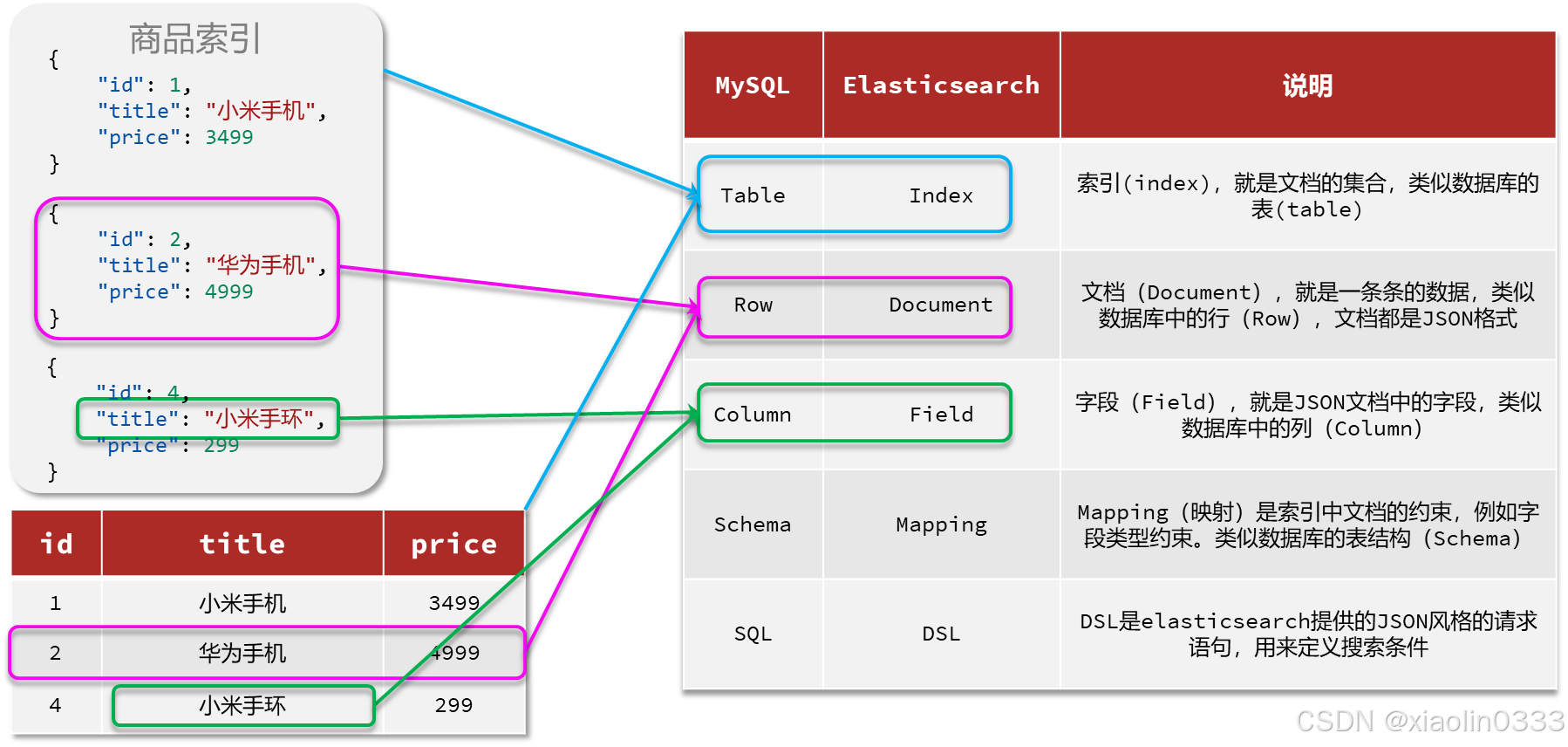
索引库操作
索引库相当于MySQL里的表,Mapping相当于对表字段的约束
Mapping映射属性
mapping是对索引库中文档的约束。
- type:字段数据类型
- 字符串:text(可分词文本)、keyword(精确值,不能分词,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date(es自己把日期对象做了序列化)
- 对象:object
- index:是否创建索引,默认为true
- true:es就会给这个字段创建倒排索引,就可以根据这个字段进行搜索或排序
- analyzer:使用哪种分词器(ik_smart、ik_max_word),只有字段类型是text才需要指定分词器
- properties:该字段的子字段
在es中,不需要管是否是数组,就算是数组,也只要指定元素的类型即可
索引库的CRUD
es中提供的API都是Restful的接口,遵循Restful的基本规范:

创建索引库
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text", // 可分词
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword", // 不可分词
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
|
【例】:
# 创建索引库
PUT /people
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"age": {
"type": "byte"
},
"email": {
"type": "keyword",
"index": "false"
},
"name": {
"type": "object",
"properties": {
"firstName":{
"type": "keyword"
},
"lastName": {
"type": "keyword"
}
}
}
}
}
}
|
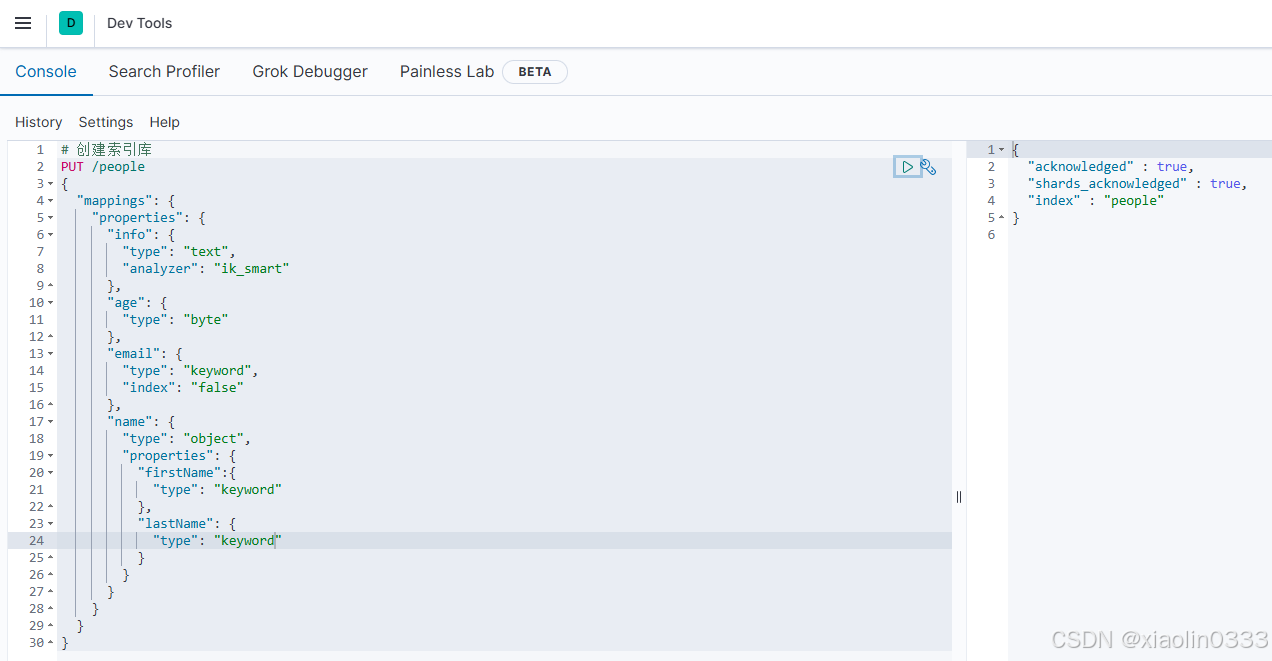
修改索引库
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
|
【例】:
# 修改索引库,新增一个sex字段
PUT /people/_mapping
{
"properties": {
"sex": {
"type": "boolean"
}
}
}
|
【注】:es中是不允许对已有索引库的字段进行修改,但是允许添加新的字段。
【原因】:假设已经在es中创建大量的倒排索引,做了大量的分词,如果此时需要修改索引库,那么前期做的所有分词都作废还要重新建立倒排索引,对于整个数据库的影响很大。
查询索引库
删除索引库
文档操作
文档的CRUD
新增文档
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
}
|
【例】:
POST /people/_doc/1
{
"info": "程序员",
"email": "xiaolin0333@qq.com",
"name": {
"firstName": "林",
"lastName": "三"
}
}
|
新增文档的时候最好指定文档id,es会根据文档id创建索引,如果不指定id,es会随机生成id,这样将来操作文档就会很不方便
修改文档
1. 全量修改
删除旧文档,添加新文档
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 文档的所有字段都要写
}
|
注:如果想要修改一个文档id不存在的文档,删除文档的时候,文档不存在,会直接新增一条文档
因此PUT请求具备了新增和修改两种功能
2. 增量修改
修改部分字段值
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
|
查询文档
# 查询文档
GET /索引库名/_doc/文档id
|
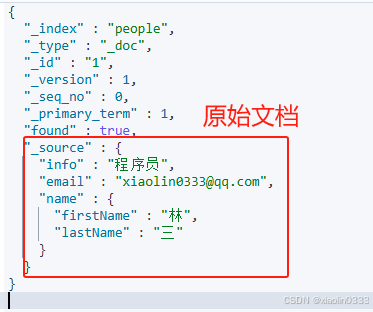
删除文档
# 删除文档
DELETE /索引库名/_doc/文档id
|
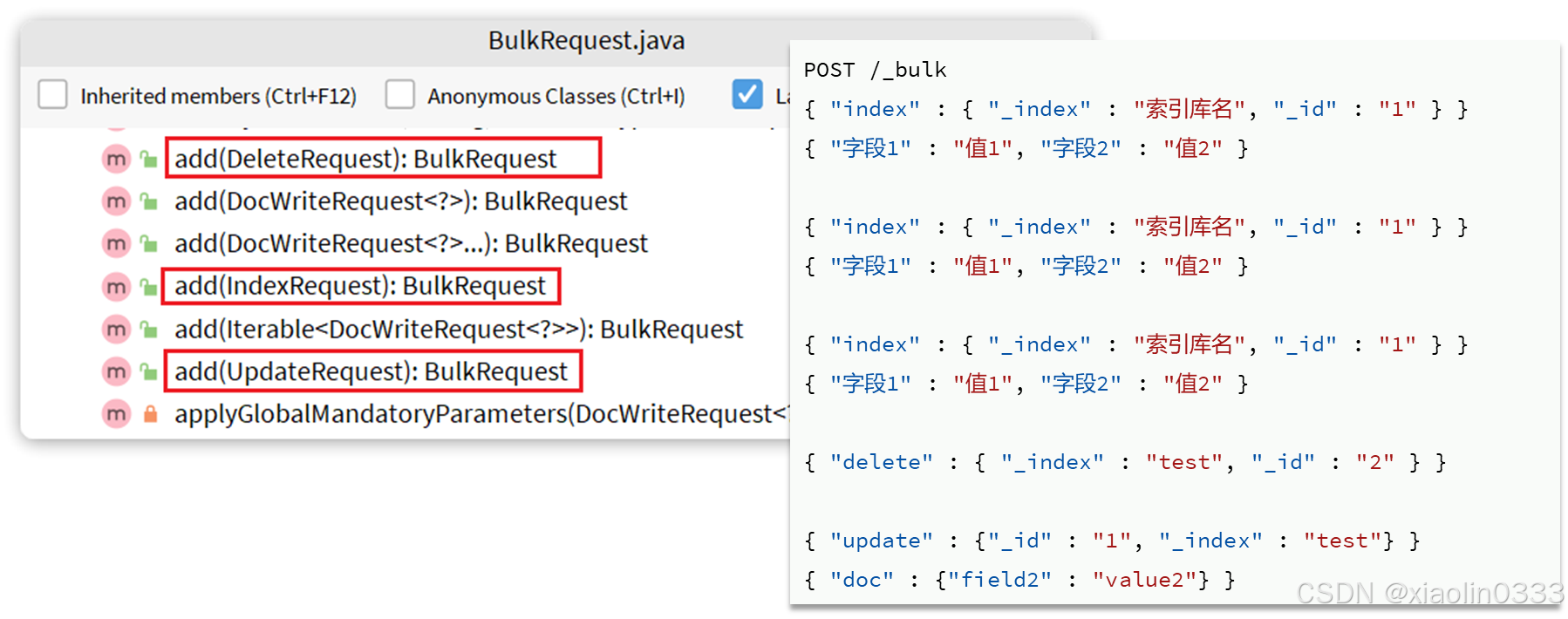
批量处理
es中允许通过一次请求中携带多次文档操作。
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } } // 新增(索引库名、id)
{ "field1" : "value1" } // 新增的文档信息
{ "delete" : { "_index" : "test", "_id" : "2" } } // 删除(索引库名、id)
{ "update" : {"_id" : "1", "_index" : "test"} } // 更新(索引库名、id)
{ "doc" : {"field2" : "value2"} } // 更新的文档信息(增量修改)
|
写的时候不能换行,只能在一行写,否则会报错
【例1】:批量新增
POST /_bulk
{"index": {"_index": "people","_id": "2"}}
{"info": "这是人", "email": "xiaolin0333@qq.com", "name": {"firstName": "林", "lastName": "三"}}
{"index": {"_index": "people","_id": "3"}}
{"info": "这是狗", "email": "cmb@qq.com", "name": {"firstName": "柴", "lastName": "犬"}}
|
【例2】:批量删除
POST /_bulk
{"delete": {"_index": "people","_id": "2"}}
{"delete": {"_index": "people","_id": "3"}}
|
JavaRestClient
客户端初始化
- 引入es的RestHighLevelClient的依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
|
- 因为SpringBoot默认ES的版本是7.17.0,所以需要覆盖默认的ES版本:
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
|
- 初始化RestHighLevelClient(这里暂时先用单元测试为例)
public class ElasticTest {
private RestHighLevelClient client;
@Test
void testConnection() {
System.out.println("client = " + client);
}
@BeforeEach
void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.140.101:9200")
));
}
@AfterEach
void tearDown() throws IOException {
if(client != null) {
client.close();
}
}
}
|
商品表Mapping映射
【业务分析】:
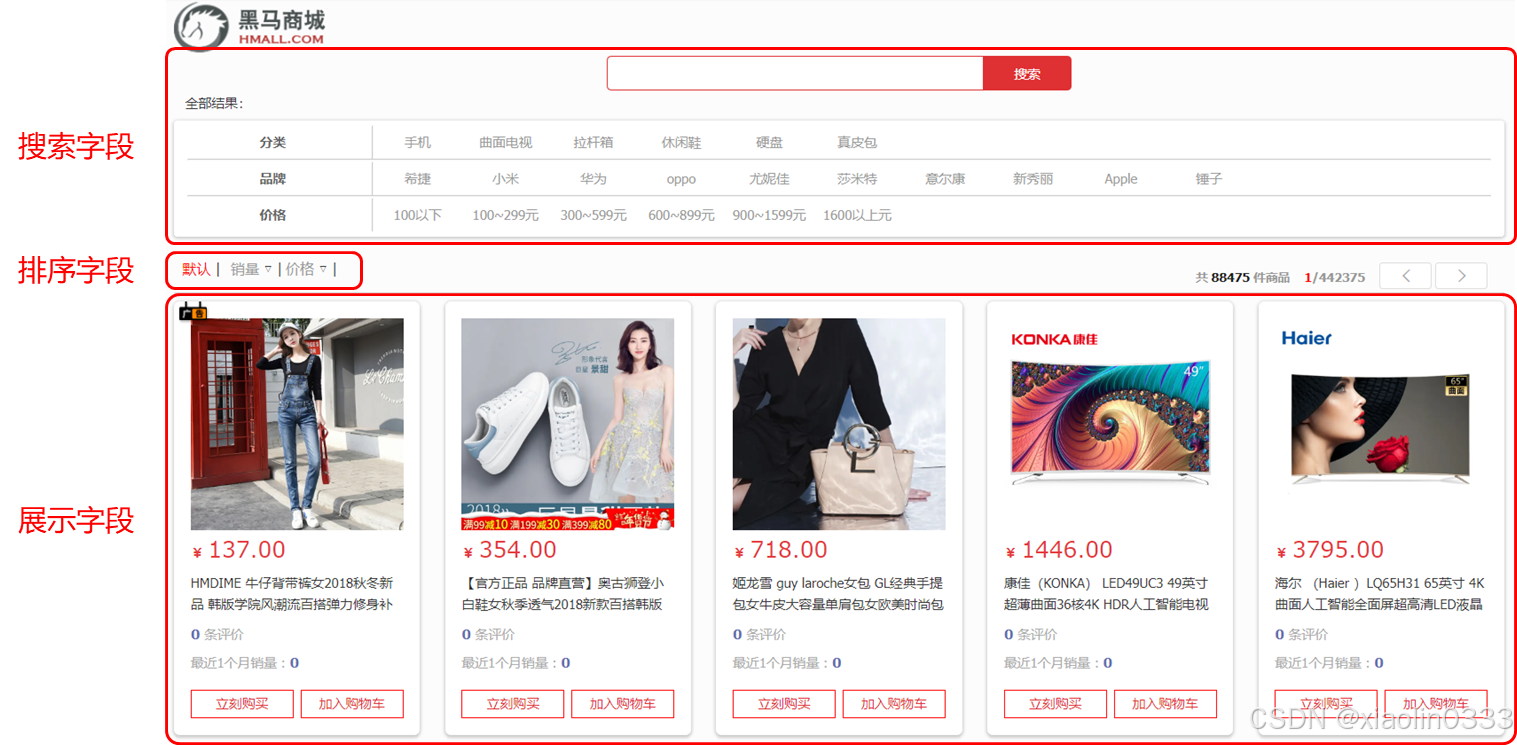
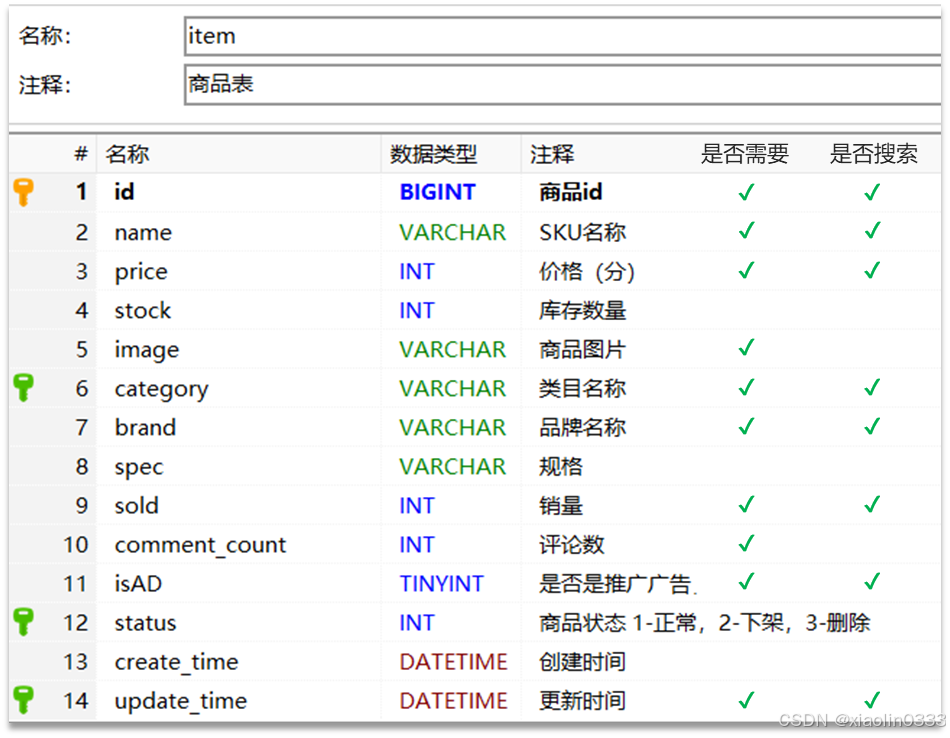
【在控制台创建Mapping映射】:
# 商品索引库
PUT /hmall
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_smart"
},
"price": {
"type": "integer"
},
"image": {
"type": "keyword",
"index": false
},
"category": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"sold": {
"type": "integer"
},
"commentCount": {
"type": "integer",
"index": false
},
"isAD": {
"type": "boolean"
},
"updateTime": {
"type": "date"
}
}
}
}
|
索引库操作
- 创建XxxIndexRequest。Xxx指:Create、Get、Delete
- 准备请求参数(Create需要)
- 发送请求。调用client.indices.xxx()方法,xxx指:create、get、exists、delete
创建索引库
创建索引库的JavaAPI和Restful接口API对比:
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("items");
request.source(MAPPING_TEMPLATE, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}
|
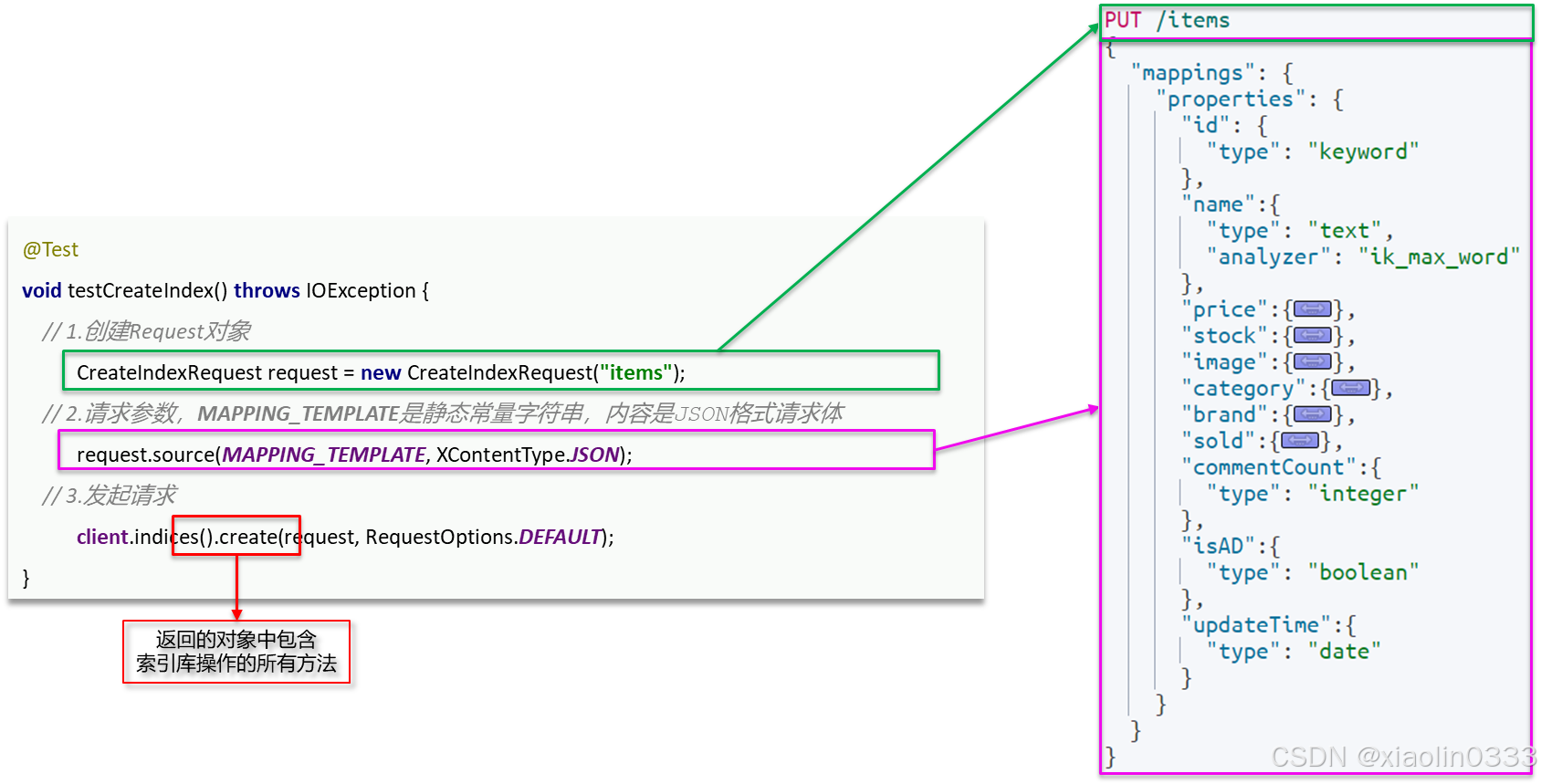
查询索引库
@Test
void testGetIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("items");
GetIndexResponse response = client.indices().get(request, RequestOptions.DEFAULT);
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
}
|
删除索引库
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("items");
client.indices().delete(request, RequestOptions.DEFAULT);
}
|
文档操作
- 初始化RestHighLevelClient
- 创建XxxRequest。Xxx指:Index、Get、Update、Delete
- 准备参数(Index和Update需要)
- 请求参数。调用xxx()方法,xxx是index、get、update、delete
- 解析结果(Get需要)
新增文档
新增文档的JavaAPI和Restful接口API对比:

@Test
void testIndexDoc() throws IOException {
Item item = itemService.getById(2018833);
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
String jsonStr = JSONUtil.toJsonStr(itemDoc);
IndexRequest request = new IndexRequest("items").id(itemDoc.getId());
request.source(jsonStr, XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
}
|
修改文档
全量修改
全量修改相当于新增,就是新增的时候文档id已经存在
局部修改

@Test
void testUpdateDoc() throws IOException {
UpdateRequest request = new UpdateRequest("items", "2018833");
request.doc(
"price", 25600,
"stock", 9999
);
client.update(request, RequestOptions.DEFAULT);
}
|
查询文档
查询文档主要是拿到_source部分
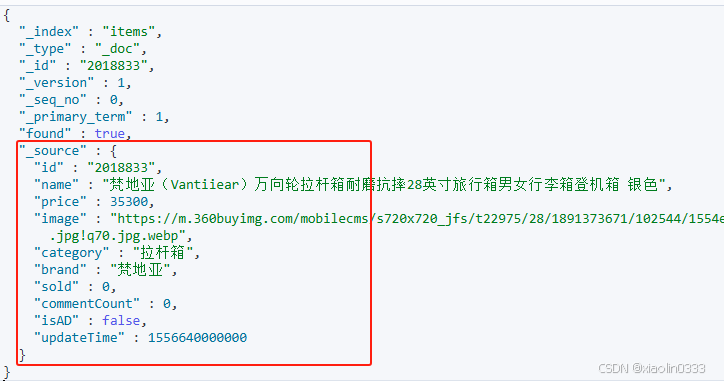
@Test
void testGetDoc() throws IOException {
GetRequest request = new GetRequest("items", "2018833");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class);
System.out.println(doc);
}
|
删除文档
@Test
void testDeleteDoc() throws IOException {
DeleteRequest request = new DeleteRequest("items", "2018833");
client.delete(request, RequestOptions.DEFAULT);
}
|
批处理
构建请求时会用到BulkRequest来封装普通的CRUD请求:
【案例】:往索引库里添加所有上架的商品
@Test
void testBulkDoc() throws IOException {
int pageNo = 1, pageSize = 500;
while(true) {
Page<Item> page = itemService.lambdaQuery()
.eq(Item::getStatus, 1)
.page(Page.of(pageNo, pageSize));
List<Item> records = page.getRecords();
if(records == null || records.isEmpty()) {
return;
}
BulkRequest request = new BulkRequest();
for(Item item : records) {
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
request.add(new IndexRequest("items").id(item.getId().toString()).source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON));
}
client.bulk(request, RequestOptions.DEFAULT);
pageNo++;
}
}
|








